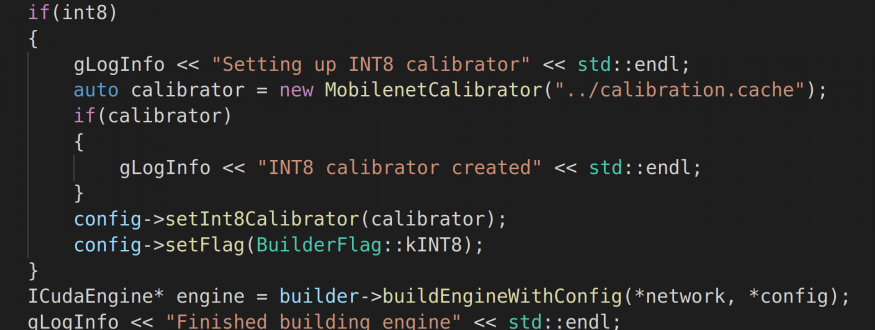
In our last blog post we compared the new NVIDIA Xavier NX to the Jetson TX2 and the Jetson Nano. Since then, we implemented some changes and updates to our benchmark tool. First, we switched from the TensorRT Python API to the C++ API and second, we are now able to convert our model to INT8 precision to speed up inference. This is done by implementing the IInt8EntropyCalibrator2-class. More information on the INT8 calibration process …
Read more