In our last blog post we compared the new NVIDIA Xavier NX to the Jetson TX2 and the Jetson Nano. Since then, we implemented some changes and updates to our benchmark tool. First, we switched from the TensorRT Python API to the C++ API and second, we are now able to convert our model to INT8 precision to speed up inference. This is done by implementing the IInt8EntropyCalibrator2-class. More information on the INT8 calibration process can be found in the NVIDIA TensorRT Developer Guide.
Furthermore, we noticed a significant speedup during inference since we started using the C++ API to build the engine, however at the time of writing we were not able to figure out the reason for that.
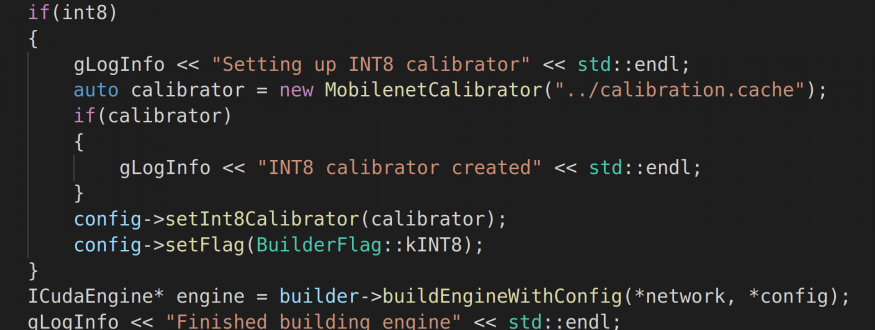
With only a few lines of code we activate INT8 precision before building the TensorRT engine
Let’s get right to the new performance results. The chart below depicts the three configurations we tested with the C++ API. The first one is the standard FP16-precision mode we used before, but now the TensorRT engine has been created by using the C++ API. In the second one we forced TensorRT to convert all layers of MobileNet SSD v2 into INT8 precision. Finally, in the third configuration we activated INT8 precision, but we gave TensorRT the option to fall back to FP16 precision, if this was the fastest implementation of one or multiple layers.
As expected, we see a rise in FPS from the first to the third configuration. In general, INT8 should be faster than FP16. Though in our case TensorRT was able to find the fastest implementation by combining FP16 and INT8 layers. Thus, activating FP16 precision as a fallback option might be the best solution to get the most out of the TensorRT optimization process.
When a model is converted to INT8 precision, we gain inference speed, but we will lose precision. This loss can be minimized by choosing a suitable set of images for the calibration process. We managed to lose only 0.67% when calculating the mAP of our new engines, which is a relative loss of 1.8% precision compared to FP16. According to NVIDIA one can minimize the loss to around 1.0% by fine tuning the calibration data set.

Depending on the model you use, the conversion to INT8 can improve its performance without sacrificing too much precision. If you did not try it out yet, you should give it a try!
Thank you for reading and see you next time.